
While thinking back to when I was first learning about microservice architecture, I recall a few related subjects that I had come across such as asynchronous/connectionless messaging. The idea is that many areas of the system can operate independently of the client that invoked them. In other words, if I click a button on a UI that tells the system to execute a process, I don’t necessarily need to wait for that process to complete before continuing on with what I was doing. For example, if you click a button to unsubscribe from a mailing list, do you REALLY need a response other than “OK”. In theory, the server should be able to queue the request and let you know that it’ll get taken care of (HTTP Code 202 Accepted). This concept is especially true with background processes. Since I’m more of a server developer than I am a front-end developer, I’m going to use a scheduled worker process to illustrate this concept.
Let’s say that our task is to stage some data so that our warehouse engineers can load it. So we’re building a service whose responsibility is to ensure the data is pulled from a number of APIs and stored in a cloud storage blob every hour so that an ELT service can pick that data up and load it into a data lake and/or data warehouse. Essentially, I’m describing the Extract portion of an ELT process, but we’re going to do it in application code because they are a bit too complex for a typical ELT package, we need the flexibility of app code to deal with the downstream providers. Since we’re in a microservice architecture, we have built out individual provider proxies for every data source; these proxies only know how to deal with those providers’ APIs and how to work with a cache.
The high level algorithm is as follows:
- Extraction manager wakes up every hour and requests that data be pulled from 5 different providers
- Each provider proxy will answer the request by pulling data from it’s respective source, whether it be a remote API, a database, a process, etc. The extraction manager doesn’t know, and it doesn’t care.
- The extraction manager will receive the result data and serialize it into a json blob that will be stored on a cloud storage account
- Our data tier is monitoring that blob (via event bus) and will pick those up and process them as they arrive, but this isn’t really our concern, it’s just for context.
The Typical Synchronous Flow
Architecturally, we have a couple different options on how to achieve that. Most engineers would first think of a client-server / request-response type approach. That is, the manager will simply make an HTTP request to an API exposed on the proxy. The proxy would make a downstream call to the data source and then return the results and the manager would store it. It would execute this process once per proxy. It could do them in parallel, or one at a time. Ok let’s be honest, most engineers would try to contain all of the extraction process in the worker, but since we’re talking about microservices, I’m going to assume that they would at least delegate this off to a different process (i.e. the proxy here).
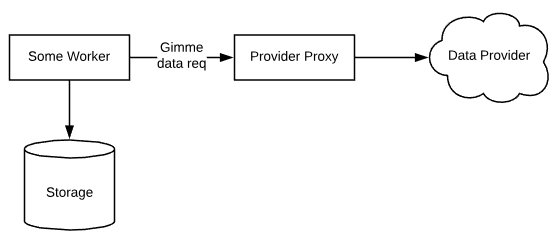
This design is easy to understand and is fairly common. The problem with it is scaling, resilience, and generally tight coupling, I think. If one of the providers is having a problem such as it went offline, or the downstream data source is unreachable for some reason, then the entire chain fails. We acknowledge that if each job was run in parallel, then others could still succeed. Since each request is held open until a response is made, there’s plenty of additional room for something to go wrong. Each proxy is going to perform differently. Responses will come in at different speeds, the connection could drop, resources could spike, we need to manage timeouts, additional error handling, etc. The manager has too much reliance on the need for specific services to do their job reliably. Also, what if I wanted to up the frequency from hourly to every minute? Some jobs may start before the previous job even finished and we’ll start to have some back pressure on open connections alone (i.e. memory usage). Depending on the size and complexity of your system, this may not be much a concern, but we’re going to try a different approach that is more in the spirit of microservice asynchronicity.
The Asynchronous Flow
Instead, we’re going to unfortunately add a little bit of complexity, but in return, we’re going to decouple the services and add some resilience as well as isolating problems to a single service instead of having those problems need to bubble up.
Instead of making a request-response type call to each individual provider, we’re going to employ a service bus to issue commands to all services. Then instead of holding a connection open until we get a response, we’re going to allow those proxies to handle the processing on their own time and then let us know when they’re done. I don’t mean that the proxy is going to contact the manager directly with the results, however, as that would cause a bi-directional dependency which is actually worse than what we started with. Instead, the proxies are going to raise an event to the bus, stating that the results are done and where they can be found.
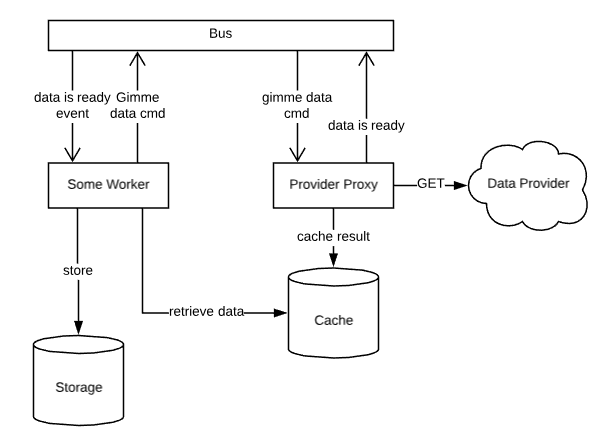
This diagram looks more complicated than it really is, depending on your service bus implementation. I’d recommend NServiceBus for something like this. Most of the complexity of messaging is abstracted away. I’m not going to go into how it works as it is out of scope of this blog, but it is fairly simple. We use NServiceBus with RabbitMQ as the message transport.
The diagram here illustrates the flow of a single command issued to the provider proxy. Here is the sequence:
- The worker wakes up and issues a command to the bus that data should be retrieved. This is an asynchronous call so it returns immediately. We don’t wait for the response, so until the proxy raises the ready event, the manager basically goes back to sleep.
- The provider proxy receives the command and begins to run its process of retrieving the data from the provider.
- When the proxy is done, it stores the results in a cache then raises an event stating that the data is ready. The event will contain any information that any subscriber (perhaps not just the manager) can use to identify the results and retrieve them from the cache.
- The manager (labeled ‘some worker’) receives the event and then retrieves the result from the cache and places it in the blob storage so that the data pipeline can take over from there.
The nice thing about most services buses is that they can be transactional. Or rather, they can be persistent in that the process that handles them must succeed before the message is “popped” from the bus forever. For example, NServiceBus provides persistent messaging and error handling. So if the proxy fails at some point, it’ll try again and again until it succeeds. After so many failures, the message gets moved to an error queue, but it is not lost. So once the problem is resolved, those messages can still be retried. Since the manager isn’t waiting for a response, there is no hard dependency on how or when that result makes it back. Does that make sense? In other words, if the proxy fails, the manager doesn’t really care, so we’re decoupled. Any errors that happen are isolated in the proxy that had the problem. Also, now neither the manager nor the proxies even know that each other exists let alone have a dependency on each other. This is benefit of using a service bus. You could achieve similar results using an ELB for service discovery, but I prefer the reliability of the bus for cases like this.
So with that in mind, let’s take a look at what it looks like in the original scenario where there are many providers involved:
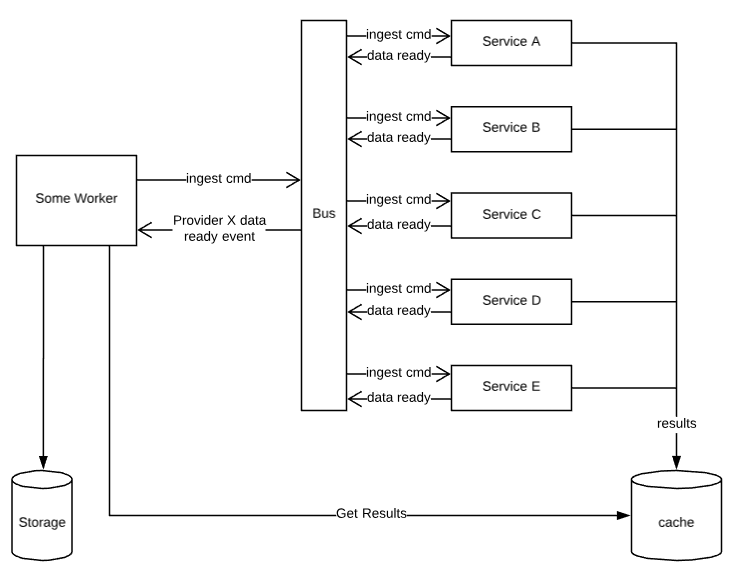
I’ve modified some of the component names to be more generic about what’s going on here (i.e. this works in many other scenarios), but this shows that the manager (‘some worker’) just issues commands for each provider. I mean, it literally fires off commands for every provider you want data from and then goes back to sleep. Each proxy receives those commands and gets to work. As each one finishes on its own time, it caches the result and then raises the event. The manager then receives those events as they come in, retrieves the results and stores them. If any of them fails, the manager doesn’t really care, it’s only issuing commands and moving successful results to storage. Nice and clean. Of course, this can be extended any way that you want for error handling, logging, notifications, etc. Just try and stay in that decoupled spirit — each service should be allowed to fail without it breaking the system.
Single Responsibility
So that begs the question: “Why not just have the proxies put the data in blob storage directly and cut out some of this back and forth?”
Well, you could! However, I disagree with the larger design in my particular case and in the spirit of SRP. In this particular case, the proxies are designed with one responsibility which is to interact with downstream providers. They’re not just for this ELT process; I want to be able to use this in other contexts as well which is why I separated out the manager. As such, I don’t want them to have any knowledge of cloud storage. For example, they would have to know where to store the files for the ELT process. I could include that information in the command (e.g. get results and store them *here*) but then what if I switch from Azure storage to Google storage? What if I need to store it in multiple locations? What if I don’t need it stored at all? Now I’d have to go change implementations in every one of those services and all of these scenarios would lead to some pretty ridiculous switching logic when the those scenarios aren’t really the responsibility of a provider like this.
You might think “oh but you’re still accessing a cache so that’s not SRP. I don’t agree. Caches are cross-cutting and are far less likely to move or change in any significant way, so I do not count it in the design consideration.
Another gain here is that the extraction process in the provider now takes on a “worker” role instead of an “application” role. It can now extract data on its own time instead of serving direct requests. So earlier, I mentioned that I may want to increase the frequency which could cause memory pressure due to the potential of overlapping jobs. Instead of holding connections open while it fetches data, it simply processes a queue. This scales better in that it doesn’t really have to scale since it doesn’t need to support more connections. This is particularly useful if the downstream provider has a connection limit/throttle since a single instance of a worker can manage this a bit better. In other scenarios, this setup can also add some value in that if the queue gets backed up, additional instances of the worker can be added. For us, we’re deployed in docker. By allowing the message handler to use as many resources as needs to clear the queue, the added load triggers the orchestrator to spin up additional containers and then spin them down as the load decreases which is very cost efficient as well as performant.
But how practical is this really?
So would I use this design in every case? Definitely not in every scenario. For example, if I had a UI that needed to query data that was already stored, would I go through this process just to stage results? Of course not. However, whenever a longer running process that could be spread across several services is encountered, I always consider this design as it ensures some level of resilience and added performance, and while it is more complex at first, I feel that the overall design is cleaner and easier to deal with.
So what what happens if you’re in a scenario where it’s a more complex process and something cannot continue or be considered “done” until various constituent pieces are completed successfully? What about in complex domains like booking or checkout, etc. Does this even work in those contexts? Absolutely, but like any other approach, there are more things that you have to incorporate to build a solid system. Check out the Saga Pattern (look up more references, there are many different angles on it). It fits either the synchronous or asynchronous architecture just fine. Use it for managing distributed processes and providing yourself with some sort of atomicity.